(This page is under construction.)
Table of Contents
Introduction
Insofar as the Space Shuttle is concerned, the Virtual AGC
Project's present goals — or if you'd prefer, my goals —
are the following:
- To provide the complete source code for the software for the
most-significant of its onboard computer systems, to the extent
allowed by U.S. law.
- To provide all of the official documentation needed to
understand that software and to work with it. See the References.
- To provide development tools suitable for working with the
software source code, and in particular for compiling/assembling
it into executable form.
- To provide an emulator suitable for running that executable
code.
- For the emulator to be integrated into space-flight simulation
systems such as Orbiter+SSU or FlightGear.
In essence, we'd like to do the same kinds of things for the
Space Shuttle's onboard computers, and in particular the
computers' software, as we have done for Apollo's onboard computer
systems and software.
I don't pretend to be putting together an "everything
about the Space Shuttle" site. If you want to know about the
Space Shuttle's Main Engines (SSME) or Reaction Control System
(RCS), or hear marvelous facts such as the maximum payload size
being a 15×60 foot cylinder weighing 65,000 pounds, then this is not
the place to look. (But that's big, isn't it?
I never knew.)
Now, there are various nuances to the statements above, such as
whether access to source code must be restricted in some ways,
rather than being freely available. And by "the" source
code, do I mean all revisions? Do I mean for all
components of the system? And by "the" development tools, do
I mean the original ones, or do I mean partial work-alikes?
And by emulation, do I mean emulation of the entire stack of code,
or just for some restricted portion of it? And besides
which, how do I really know which documents may be relevant to
these matters and which may be completely irrelevant?
For example, although I explicitly said above that this isn't
the site to come to if you want to learn about engines (SSME), the
engines were in fact controlled by a dedicated controller
containing two redundant Honeywell
HDC-601 digital computers ... so shouldn't those computers
and their software be covered here?
Answers to those questions will become clear in the sections
below ... or at least, clearer than they are now. There are
a lot of gray areas. And I don't pretend to know all of the
answers yet, so we may need to await future events to have a
more-complete picture. But there aren't necessarily unique,
permanently-correct answers anyway. One thing I can say
unequivocally is that integration into space-flight simulation
systems is my hope rather than anything that I'll actively pursue
personally; integration is the prerogative of the developers of
those space-flight simulators, rather than mine, if they feel it's
worthwhile for them. But it's a bit premature to worry about
that yet.
The upshot is that my explanation of the Shuttle's computer
systems will by necessity be rather limited. The system is
simply too complex, and there are too many resources already
available on the web for me to suppose that a presentation by a
johnny-come-lately like me would be worthwhile or even interesting
about a topic this big. Perhaps the best place to get a
general introduction would be Chapter
4, "Computers in the Space Shuttle Avionics System", of James
Tomayko's Computers in Spaceflight: The NASA Experience,
but there are numerous other documents in our Shuttle
Library to provide more detail.
With that said, here's a brief synopsis. As with any
engineering system of substantial complexity, prepare to descend
into acronym hell!
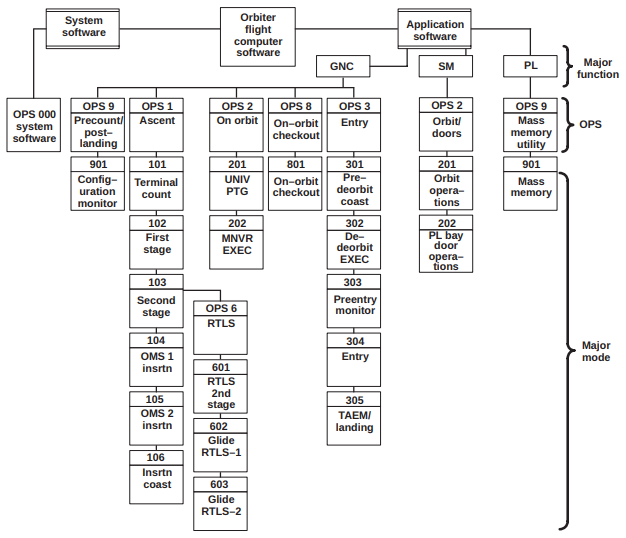
The portion of the Shuttle's full avionics system which primarily
concerns us is the Data Process System (DPS), which
includes the General Purpose Computers (GPC), the crew
interface (display and keyboards), the mass-memory units, and the
data-bus network interconnecting all of them. Here's a
diagram, swiped from the aforementioned Computers in
Spaceflight, that gives a very high-level view of the system
architecture:
As you can see, there were five separate GPCs. Each of the
GPCs on later flights was an AP-101S computer, designed and
manufactured by IBM's Federal Services Division (as were the
Apollo LVDC or Gemini OBC, though the GPC was not similar to
them in any noticeable way). Although I may not talk about
the AP-101S much, it's worth mentioning that it was a kind of
embedded version of the IBM System/360 mainframe, in that it
shared roughly the same assembly language, known as
Basic
Assembly Language (BAL).
Aside: To be perfectly
pedanticaccurate, the GPCs were originally
AP-101B computers. The AP-101S is an upgrade of the
AP-101B, replacing 416KB of core memory with 1024KB of
semiconductor (CMOS) memory, and possibly other improvements
that I've so far not been able to identify for certain,
though there are various machine-code instructions that I
believe were newly-added in the AP-101S. The upgrade
effort began in 1989, and was first flown in 1991 on STS-37
with software version OI-8F. More on the topic of
flight-software versioning will appear later.
Four of the GPCs nominally redundantly ran
identical
software, known as the
Primary Flight Software (PFS)
atop the
Flight Control Operating System (FCOS).
PFS and FCOS together are collectively referred to as the
Primary
Avionics Software Subsystem (PASS).
Aside: In spite of this
technical distinction between the acronyms PFS and PASS, I
find in practice (and have been chided by veterans of the
Shuttle project) that the term PASS was always used in
preference to PFS. In other words, people speak of
PASS vs BFS rather than PFS vs BFS, and stare at you blankly
if you mention PFS to them. Since that is the common
usage, I'm going to adopt it throughout the remainder of
this article, and will not bull-headedly use the acronym PFS
(even though I think it's technically correct) even where
the distinction vs PASS is significant.
Nominally, the behaviors of these four copies of FCOS were
synchronized ... not on a CPU-cycle by CPU-cycle basis, but to
the extent that inputs to the GPCs from the spacecraft, as well
as commands output from the GPCs to the spacecraft, occurred at
the same time. In particular, the fact that outputs from
the GPCs were synchronized allowed detection if one of the GPCs
was behaving abnormally. I say they did this "nominally",
because this extreme level of redundancy was warranted only
during critical flight phases ... in particular, during ascent
and reentry. During the more-leisurely phases of the
mission, if additional computing power was needed, the four
principal GPCs did not necessarily need to run identical,
redundant software.
The fifth GPC instead ran the
Backup Flight Software (BFS),
created entirely separately from PASS in a clean-room
fashion. This fifth GPC served roughly the same purpose in
the Shuttle as the Abort Guidance System (AGS) did in the Apollo
LM. BFS was specialized for abort functionality, i.e.,
reentry in the absence of a reliable set of GPCs running
PASS. And as I said above, this capability was really
(potentially) needed only during ascent or reentry.
The data buses interconnecting the GPCs and peripheral devices,
physically and electrically, were MIL-STD-1553 buses.
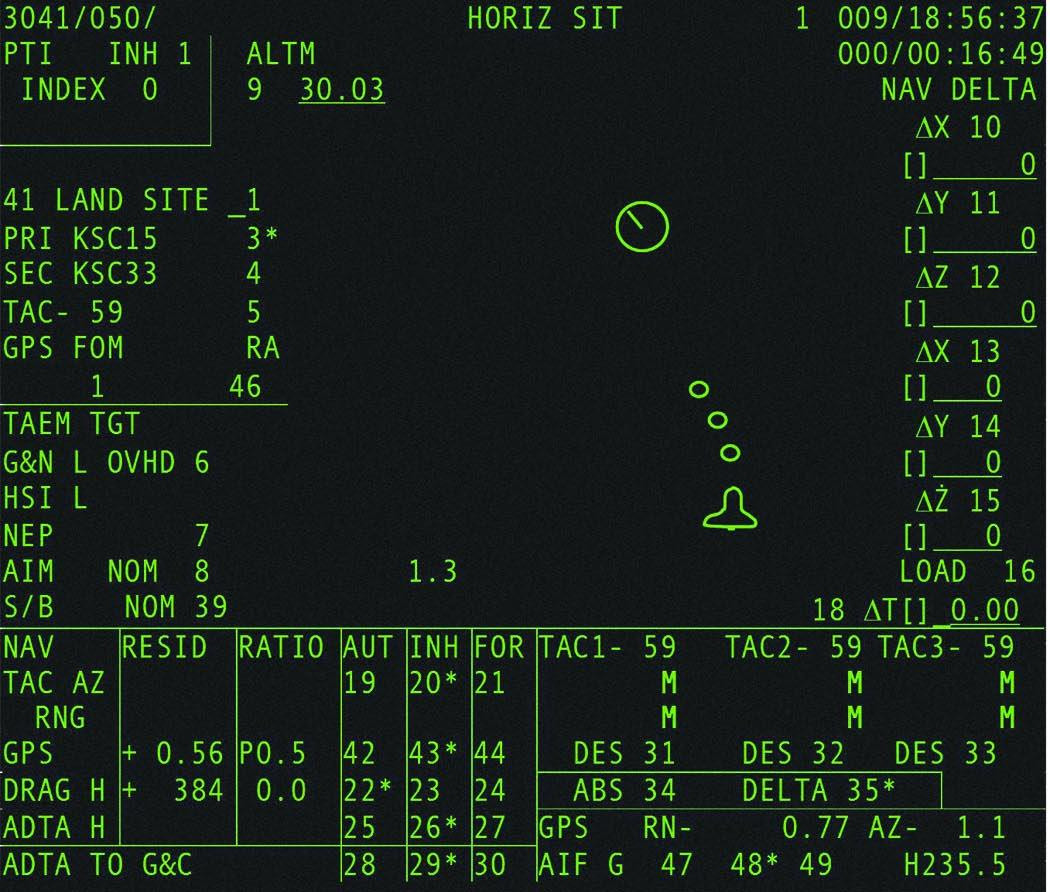
The crew-interface devices included:
- 26 line by 51 character displays, capable also of
displaying some graphics. Prior to about the year
2000, the pilots had 3 of these displays and the crew
specialist had 1; they were monochrome (green text on black
background) cathode-ray tubes (CRTs). After 2000, the
CRTs were replaced by multi-color liquid crystal displays
(LCDs), 9 for the pilots and 2 elsewhere.
Collectively, the CRTs and LCDs were referred to as Multifunction
Display Units (MDUs).
- Keyboards. The pilots had 2 of these, and the
mission specialist station had a 3rd.
The pre-2000 configuration was known collectively as the Multifunction
CRT Display System (MCDS), while the post-2000
configuration was known as the Multifunction Electronic
Display Subsystem (MEDS).
In the diagrams below, the pre-2000 configuration is shown on
the left, while the post-2000 configuration is shown on the
right. Notice that the LCD-based displays (on the right)
have 6 buttons along the bottom edges that the CRTs (on the
left) lack, as well as being taller relative to their
width. The LCDs continued to display 51×26 textual
characters, just as the CRTs had, but the text was scrunched
into the upper part of the screen, while a strip along the
bottom of the LCD could display additional stuff that the CRTs
hadn't been able to, such as menu options selectable by the
edge buttons. These differences were transparent to the
PASS / BFS flight software, because the additional stuff
displayed along the bottom was not controlled by the PASS /
BFS software. In contrast, keyboards were the same in
type and number throughout the duration of the Shuttle
program.
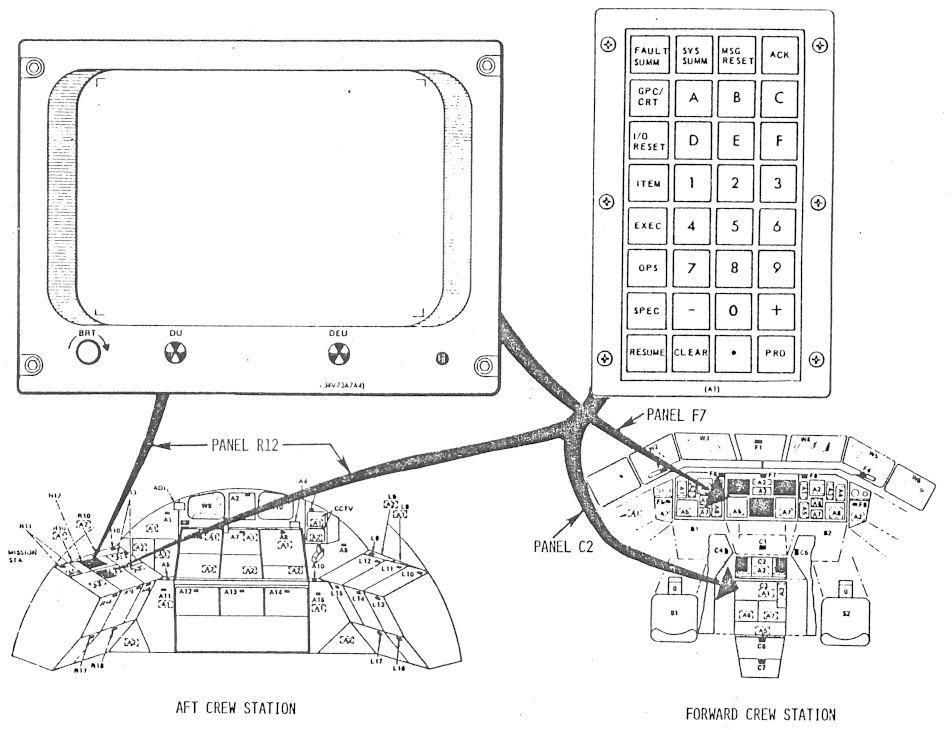
There's a more-inclusive diagram below (click to
enlarge) of the entire
older configuration of the
avionics system, if you feel the need for one. Personally,
I'm just including it because it's colorful, and you'll need to
dig into the actual documentation if you want real detail.
By the way, you can tell it's the older configuration (MCDS)
rather than the newer one (MEDS), because if you look in the
upper-left area, you'll see "CRT 1", "CRT 2", "CRT 3", and
(somewhat below the others) "CRT 4", rather than the 11 MFDs
you'd see in the newer configuration:
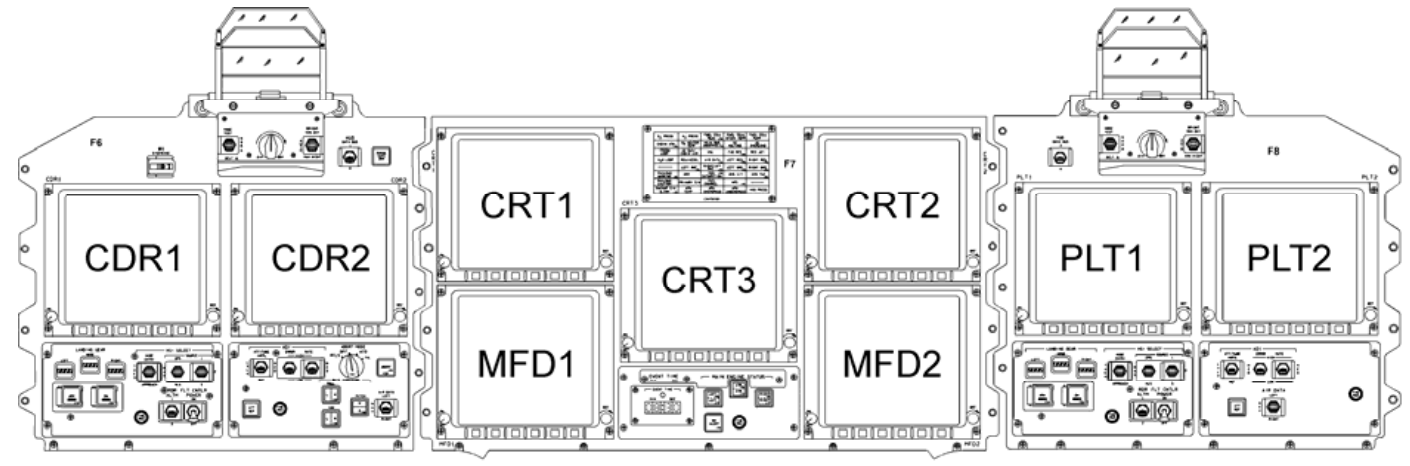
Below, on the other hand, is an extremely-informative diagram of
display-system interconnections that specifically for the newer
MEDS configuration. Don't be confused by the fact that
some of the LCDs are designated by names like "CRT
N",
because they're
not CRTs; they're just legacy names!
Like the AGC, AGS, and LVDC, which were programmed essentially
in the assembly language native to their CPU types, the Flight
Control Operating System (FCOS) was written the assembly
language of the AP-101S CPU. But once you get past those
infrastructural software components, the bulk of PASS
application code was written in a higher-level language called
HAL/S, as was the BFS.
The DPS
Overview Workbook explains the overall structure of PASS
better than I can:
"PASS software consists of two types of software:
system software and application software. System software runs
the GPC. It is responsible for tasks such as GPC–to–GPC
communication, loading software from MMUs, and timekeeping
activities. Application software is software that runs the
orbiter. This includes software that calculates orbiter
trajectories and maneuvers, monitors various orbiter systems
(such as power, communications, and life support), and
supports mission–specific payload operations. The application
software is divided into broad functional areas called major
functions; in turn, each major function consists of
Operational Sequences (OPS), which are loaded into the GPCs
for each major phase of flight.
"Finally, each OPS has one or more Major Modes (MMs) that
address individual events or subphases of the flight."
Schematically, you can see in the diagram below how the
application software was structured, at least in one version of
the flight software. Over the decades in which the
Shuttle's flight software was in use, there were certainly
changes to this structure.
References
All documents I can find that I feel are relevant to discussion
of the Space Shuttle's onboard computer systems and their software
have been collected on our Space Shuttle Library page.
That should be your first stop in a documentation
pilgrimage! However, here are some websites that have
additional documents that you may find interesting, and which may
still contain relevant materials that I've overlooked:
PASS, BFS, and Other Shuttle Source Code
I have become aware of the survival of some late
revisions of the Shuttle's flight software, both primary
(PFS/PASS) and backup (BFS, partial only). This is
remarkable, given that a former developer of Shuttle software has
told me that:
"When NASA shut down the Space Shuttle project, they erased all
of the backup storage media — since there WAS NO REQUIREMENT for
saving source code! Most of the HAL/S compiler and related
tools (like ... other support software were not saved), but all
of the HAL/S-based flight code was preserved."
In fact, I filed a Freedom of Information Act (FOIA) request with
NASA's FOIA Office to get a copy of the flight software from NASA,
but after several months of looking around they asserted that they
didn't have a copy of it. So apparently NASA fully lived up
to the lack of a requirement for preserving it, in spite of the
assertion of my informant that the flight code had in fact been
mysteriously saved (somewhere) after all. My developer
informant also told me that the Shuttle flight-code was the
most-expensive software-development project of all time.
Good job all around, U.S. Government agencies, preserving
tax-payer investment!
But I digress.
Unfortunately, confirming that the source code for the
Shuttle's flight software still exists is not the same thing as
saying that I've convinced anybody to give me all of it.
Without being too specific, I will simply say that I presently
have significant quantities of PASS source-code files in hand,
along with some BFS files, but that I am not at liberty to show
them to you due to issues which I hope can eventually be
resolved. Indeed, I can't even necessarily tell you
yet everything I have managed to acquire. It's an unpleasant
situation that I hope and expect to improve over time.
On the other hand, here is some software source code we do
have, and which you can see right now in our source tree:
- HAL/S-FC — the HAL/S compiler, used to actually compile PASS
and BFS. More specifically, HAL/S-FC
release 32V0, written mostly in an enhanced version of the
XPL high-level language, with bits in BAL (IBM 360 Basic
Assembly Language) and in AP-101S assembly language as
well. More on
this below.
- XCOM — the source code for the original "standard" XPL
compiler. Alas, it is guaranteed not to compile
HAL/S-FC, since HAL/S-FC was written in an enhanced version of
the XPL language, which I call "XPL/I", but which Intermetrics
unfortunately continued to call just "XPL". I will persist
in calling it XPL/I, however, because there are reasons the
distinction is important. Intermetrics's compiler for
XPL/I, to the best of my knowledge, has not survived the end of
the Shuttle program. Nevertheless, there are reasons why
the source code for the standard compiler remains useful, and
perhaps those reasons will become clear below. Although it
is not the contemporary software used during Shuttle
development, I have
myself written an XPL/I compiler called XCOM-I which
is capable of compiling HAL/S-FC.
Is this the Original Source Code?
To the extent that we can present the contemporary source
code for Shuttle-related software here, or to work with it using
the tools provided on this site, some alterations from the
original source code files have been needed. We hope that
these changes are not substantive, but a difference is a
difference, and you're entitled to know about it if you're
interested.
For one thing, Virtual AGC header blocks, consisting of program
comments, are added at the top every contemporary file we receive,
so that you can understand the provenance of the files as much as
possible. These comments are crafted in a way that lets you
distinguish such "modern" comments from the original contents of
the files.
Flight software files, when they become available, are
expected to be "anonymized" or "depersonalized", so as to remove
all personally-identifying information related to the original
development teams; thus, whenever the name or initials of a
programmer are discovered in the program comments of Shuttle
flight software, we have replaced them by a unique but impersonal
numerical codes. This is at the behest of some holders of
the original source materials, as a condition for obtaining the
software. Whether this is a temporary or permanent
condition, I cannot say.
Most significant, I expect, is the fact that the character
encoding of all contemporary Shuttle source code has been
completely changed. This necessity arises directly or
indirectly from the fact, unfortunate from our point of view, that
the contemporary character-encoding system used was an IBM system
called EBCDIC (Extended Binary Coded Decimal Interchange Code),
while modern source code (as far as I know) is universally encoded
using 7-bit ASCII (American Standard Code for Information
Interchange) or extension of it such as UTF-8. But EBCDIC
and ASCII are essentially 100% incompatible, with only rare,
accidental overlaps. The recoding of the source-code files
from EBCDIC to ASCII has been done before we ever received any of
the files, and was performed by unknown people, at an unknown
time, using an unknown process. Nor was it always perfectly
done, and has required occasional corrections by us.
Moreover, the EBCDIC vs ASCII issue isn't quite as simple as the
preceding paragraph suggests, because not all of the EBCDIC
characters used originally actually have ASCII equivalents.
There are special considerations regarding how you need to work
with HAL/S source code in light of those characters not supported
by ASCII.
Here are the general rules:
- HAL/S source code should be encoded using 7-bit ASCII
characters.
- Two characters originally used in HAL/S source code and in the
original documentation, namely the logical-not character "¬" and
the U.S. cent character "¢", are not present in 7-bit
ASCII. So instead, we use the ASCII characters "~" and
"`", respectively, in place of them. For example,
every time you might have seen something like "x ¬=
y" in the original HAL/S source code or documentation,
we'd expect "x ~= y" instead!
- A compiler directive of the form "D VERSION v"
was sometimes used in original HAL/S source code or
template-library files. Here, "v" is a
numerical version code in the range of 1 through 255, represented
as a single EBCDIC character. To reiterate, a single
character position in this compiler-directive string must
represent up to a 3-digit version number. The way they did
this originally was simply to pretend that the version code was
the numeric byte encoding for a character, and to insert that
single-byte numeric code into the string. For example, if
the version was 1, then instead of using the character "1" in
the compiler directive, the numerical byte 1 was inserted.
This would have been legal in EBCDIC, even though rather
inconvenient since in most cases the character would have been
unprintable. In ASCII or UTF-8, the problem goes beyond
that, and such a single-character usage doesn't even represent a
valid ASCII or UTF-8 character half of the time. So we
cannot continue to follow this odd practice. Our change is
to instead require this compiler directive to have the form "D
VERSION xx", where xx is a
2-character string of hexadecimal digits.
Aside: With that said, if your
operating system supports UTF-8 character coding rather than
simple 7-bit ASCII, you can continue to use "¬" and "¢" in
HAL/S source code. The compiler transparently converts
them to "~" and "`" during the compilation, and then converts
them back to "¬" and "¢" in printouts or in messages it
displays. In particular, this does work fine in Mac OS
and Linux, though there may be special considerations trying
to do this in Microsoft Windows, discussed later. In
some of the source code we receive, ¬ has instead already been
replaced by "^". Thus any software we provide also
silently converts "^" to "~".
A longer explanation is that for some decades now, the most-common
character encoding in the U.S. has been 7-bit ASCII, 128 characters
in all, sometimes called "plain vanilla" ASCII or just
"ASCII". But since the Space Shuttle's flight software was
originally developed on IBM mainframe systems like System/360,
rather than using ASCII it used an 8-bit character-encoding scheme
called EBCDIC. It's pretty difficult to find any two EBCDIC
tables that agree on all 256 characters, because various IBM systems
seemed to have used slightly-different versions of EBCDIC. But
here are ASCII and EBCDIC tables I pulled from Wikipedia that give
the basic idea:
| ASCII (1977/1986) |
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
A |
B |
C |
D |
E |
F |
| 0x |
NUL |
SOH
|
STX
|
ETX |
EOT |
ENQ |
ACK
|
BEL |
BS |
HT
|
LF
|
VT
|
FF
|
CR |
SO
|
SI
|
| 1x |
DLE
|
DC1
|
DC2
|
DC3
|
DC4
|
NAK
|
SYN |
ETB
|
CAN |
EM
|
SUB |
ESC |
FS
|
GS
|
RS
|
US
|
| 2x |
SP
|
! |
" |
# |
$ |
% |
& |
' |
( |
) |
* |
+ |
, |
- |
. |
/ |
| 3x |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
: |
; |
< |
= |
> |
? |
| 4x |
@ |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
| 5x |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
[ |
\
|
] |
^ |
_
|
| 6x |
` |
a
|
b
|
c
|
d
|
e
|
f
|
g
|
h
|
i
|
j
|
k
|
l
|
m
|
n
|
o
|
| 7x |
p
|
q
|
r
|
s
|
t
|
u
|
v
|
w
|
x
|
y
|
z
|
{ |
|
|
} |
~ |
DEL |
| EBCDIC |
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
A |
B |
C |
D |
E |
F |
| 0x |
NUL |
SOH
|
STX
|
ETX |
SEL
|
HT |
RNL
|
DEL |
GE
|
SPS
|
RPT
|
VT |
FF |
CR
|
SO |
SI
|
| 1x |
DLE
|
DC1
|
DC2
|
DC3
|
RES/
ENP |
NL
|
BS
|
POC
|
CAN |
EM
|
UBS
|
CU1
|
IFS |
IGS |
IRS |
IUS/
ITB
|
| 2x |
DS
|
SOS
|
FS
|
WUS
|
BYP/
INP |
LF |
ETB |
ESC |
SA |
SFE
|
SM/
SW |
CSP
|
|